NICAR 2019: Mapping with R - Census data
Andrew Ba Tran
3/8/2019
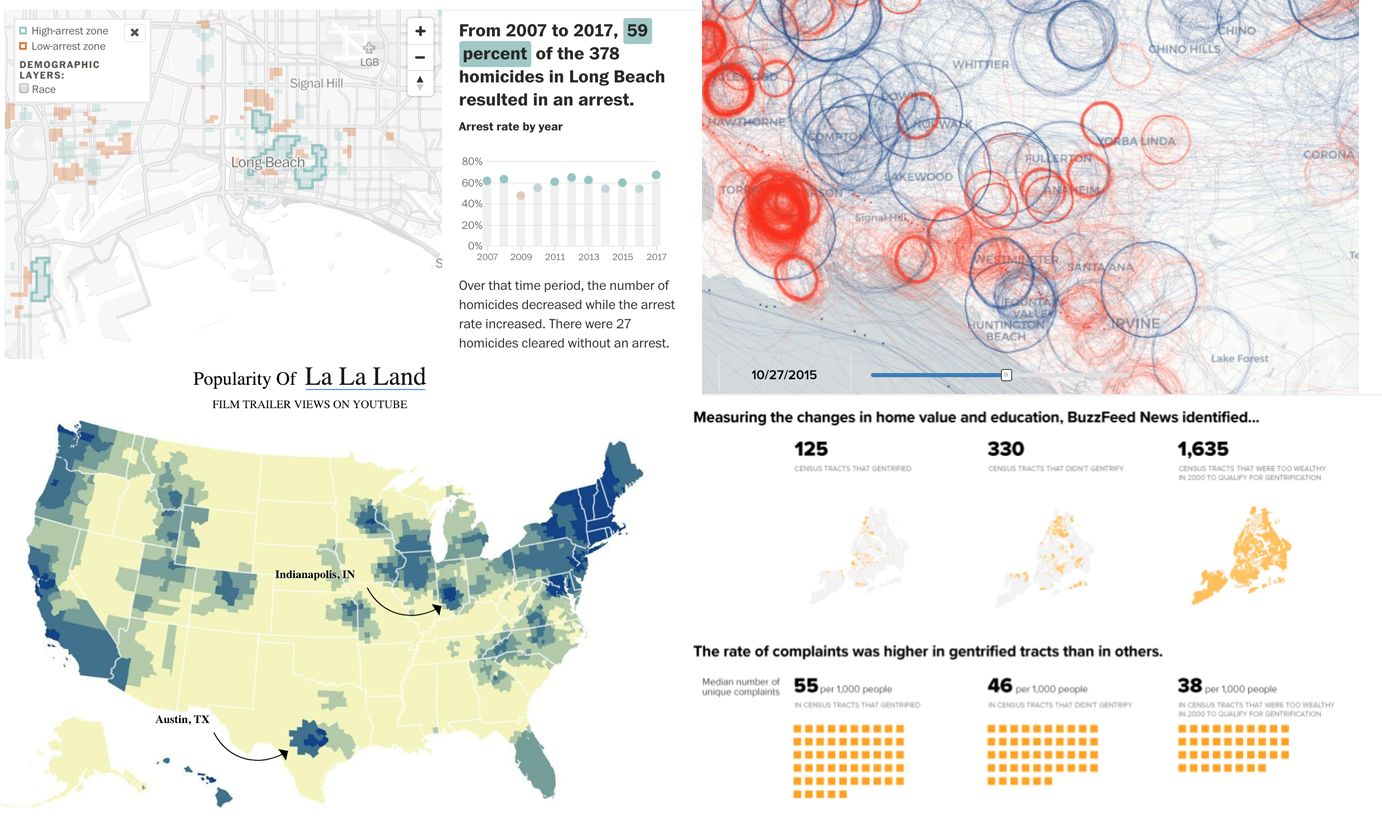
Maps are fun
Press s to see my lecture notes.
Maps normally

Maps normally
- Download data and transform data
- Excel
- Find and download shapefiles
- Census TIGER
- Import maps and join with data and style
- ArcGIS or QGIS
- Export and tweak for style further
- Tableau, CartoDB, Illustrator
Mapping with R
Why map in R?
- Scripting and reproducibility
- Transparency and trust
- Easily interface with APIs for data and shapefiles
- Life is already complicated
- Your process doesn’t have to be
Today
- Create static maps and interactive maps with geolocated data
- We’ll be using the more-recent packages in the R GIS community
- simple features
- leaflet
- Access the Census API to download data and use what we’ve already learned to join that data to shapefiles to make choropleth maps– both interactive and static.
Basics
There are two underlying important pieces of information for spatial data:
- Coordinates of the object
- How the coordinates relate to a physical location on Earth
- Also known as coordinate reference system or CRS
CRS
- Geographic
- Uses three-dimensional model of the earth to define specific locations on the surface of the grid
- longitude (East/West) and latitude (North/South)
- Projected
- A translation of the three-dimensional grid onto a two-dimensional plane
CRS

Raster versus Vector data
Spatial data with a defined CRS can either be vector or raster data.
- Vector
- Based on points that can be connected to form lines and polygons
- Located with in a coordinate reference system
- Example: Road map
- Raster
- Are values within a grid system
- Example: Satellite imagery
sf vs sp
- An older package, sp, lets a user handle both vector and raster data.
- This class will focus on vector data and the sf package.
Shape files
Though we refer to a shape file in the singular, it’s actually a collection of at least three basic files:
- .shp - lists shape and vertices
- .shx - has index with offsets
- .dbf - relationship file between geometry and attributes (data)
All files must be present in the directory and named the same (except for the file extension) to import correctly.
The plan
- Map blank shape file after downloading
- Join Census data to blank shape file and map
- Use R package Tigris to download shape file
- Use R package censusapi to download census data and join to new shape file
- Use tidycensus to download Census data and the shape file all at once
Mapping a simple shape file
We’ll start by importing in a shape file of state boundaries from the Census.

Mapping a simple shape file
st_read() is the function to import the shapefile.
Type out the code below or copy and paste it into the console or run simple_states from the static_maps_slides.Rmd file
library(ggplot2)
library(sf)
fifty_location <- "data/cb_2017_us_state_20m/cb_2017_us_state_20m.shp"
fifty_states <- st_read(fifty_location)Mapping a simple shape file
View(fifty_states)
Map fifty_states
Map with ggplot2 functions and geom_sf
ggplot(fifty_states) + geom_sf()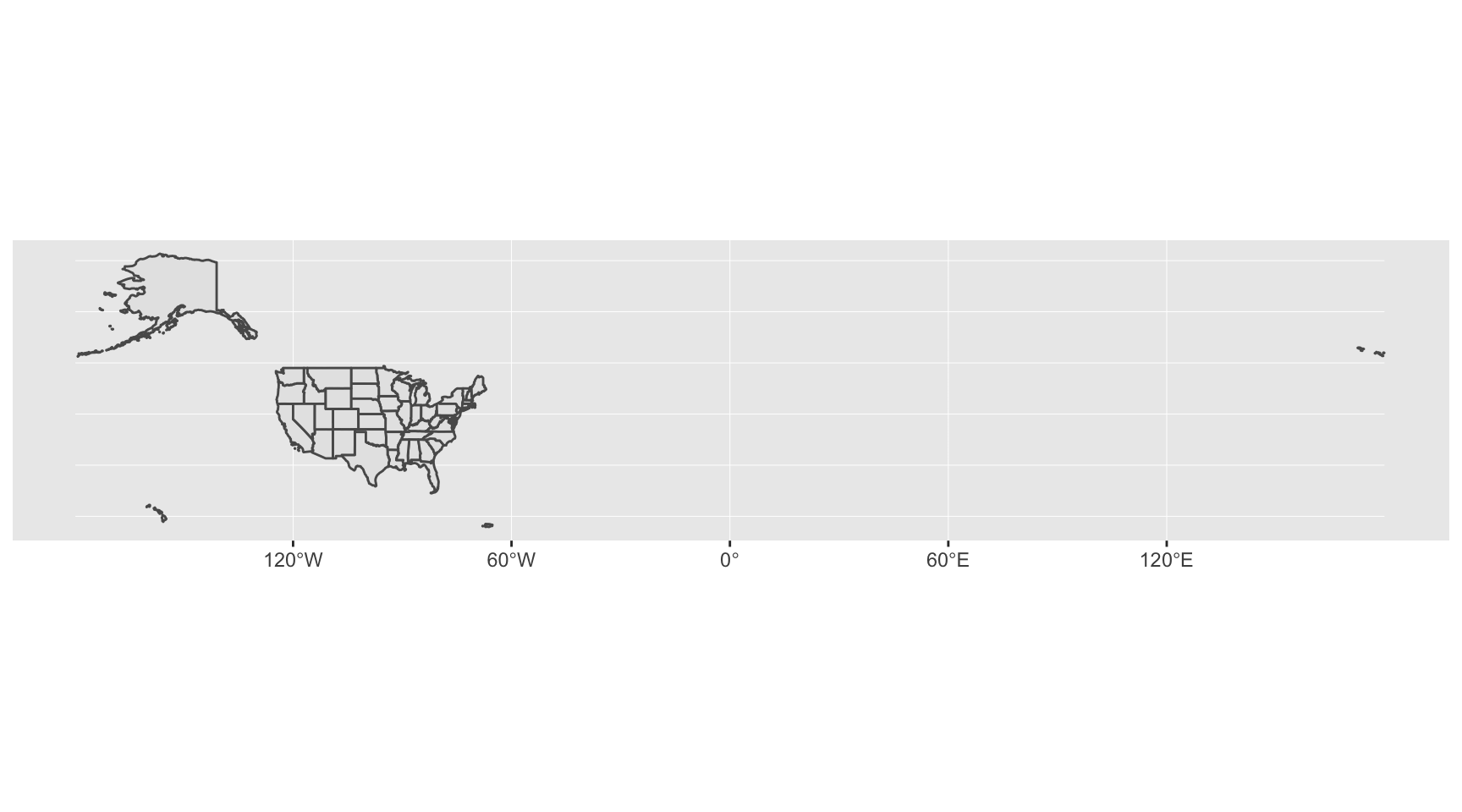
Join it to data
Let’s pull in population data from CensusReporter.org
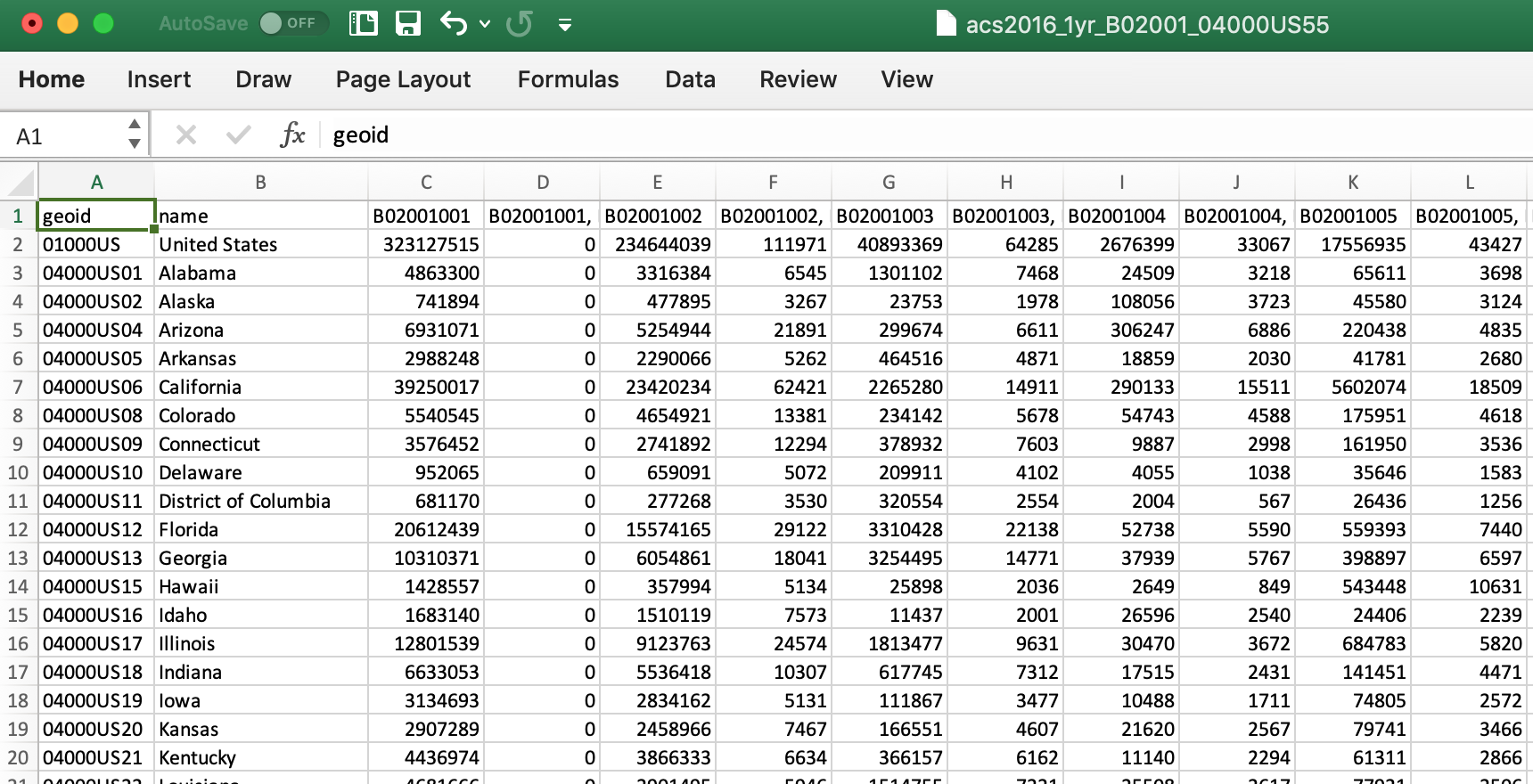
Import the data
Using read_csv() from the readr package.
library(readr)
populations <- read_csv("data/acs2016_1yr_B02001_04000US55.csv")
Import the data
View(populations)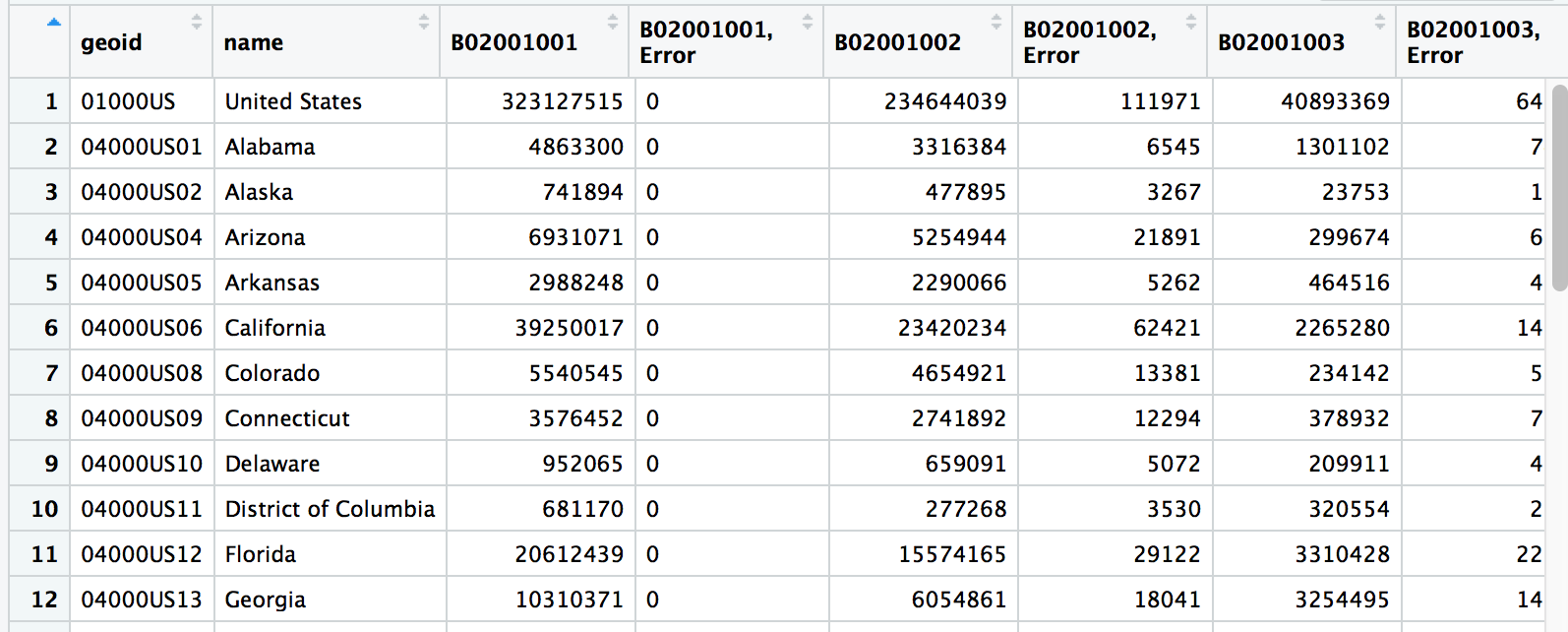
Join data to blank shapefile and map
ncol(fifty_states)## [1] 10library(dplyr)
fifty_states <- left_join(fifty_states, populations,
by=c("NAME"="name"))Did it work?
ncol(fifty_states)## [1] 31There are a lot of variable names in this data frame. Check them out.
colnames(fifty_states)## [1] "STATEFP" "STATENS" "AFFGEOID"
## [4] "GEOID" "STUSPS" "NAME"
## [7] "LSAD" "ALAND" "AWATER"
## [10] "geoid" "B02001001" "B02001001, Error"
## [13] "B02001002" "B02001002, Error" "B02001003"
## [16] "B02001003, Error" "B02001004" "B02001004, Error"
## [19] "B02001005" "B02001005, Error" "B02001006"
## [22] "B02001006, Error" "B02001007" "B02001007, Error"
## [25] "B02001008" "B02001008, Error" "B02001009"
## [28] "B02001009, Error" "B02001010" "B02001010, Error"
## [31] "geometry"What are the variables
- STATEFP is the state fips code.
- That stands for the Federal Information Processing Standard. It’s a standardized way to identify states, counties, census tracts, etc.
- GEOID is also part of the fips code.
- In this instance it’s only two digits wide.
- The more specific you get into the Census boundaries, the longer the number gets.
What are the variables
- B02001001, B02001002, etc.
- This is reference to a Census table of information.
- For example, B02001001 is total population for that polygon of data in that row
- When you export data from the Census, the variables get translated to this sort of format
- You’ll have to remember when you download it or look it up.
- B02001001, Error
- Margin of error included because these are just estimates, after all
- geometry
- This is the CRS data
Map with the new data
- Map with
geom_sf() - Fill with B02001001
- Leave out Hawaii and Alaska for now
forty_eight <- fifty_states %>%
filter(NAME!="Hawaii" & NAME!="Alaska" & NAME!="Puerto Rico")
ggplot(forty_eight) +
geom_sf(aes(fill=B02001001)) +
scale_fill_distiller(direction=1, name="Population") +
labs(title="Population of 48 states", caption="Source: US Census")The functions
forty_eight <- fifty_states %>%
filter(NAME!="Hawaii" & NAME!="Alaska" & NAME!="Puerto Rico")
ggplot(forty_eight) +
geom_sf(aes(fill=B02001001)) +
scale_fill_distiller(direction=1, name="Population") +
labs(title="Population of 48 states", caption="Source: US Census")- %>% and filter
- ggplot()
- geom_sf() and aes() and the fill variable
- scale_fill_distiller() and the direction and name variables
- labs() and title and caption variables
New map with Census data
forty_eight <- fifty_states %>%
filter(NAME!="Hawaii" & NAME!="Alaska" & NAME!="Puerto Rico")
ggplot(forty_eight) +
geom_sf(aes(fill=B02001001)) +
scale_fill_distiller(direction=1, name="Population") +
labs(title="Population of 48 states", caption="Source: US Census")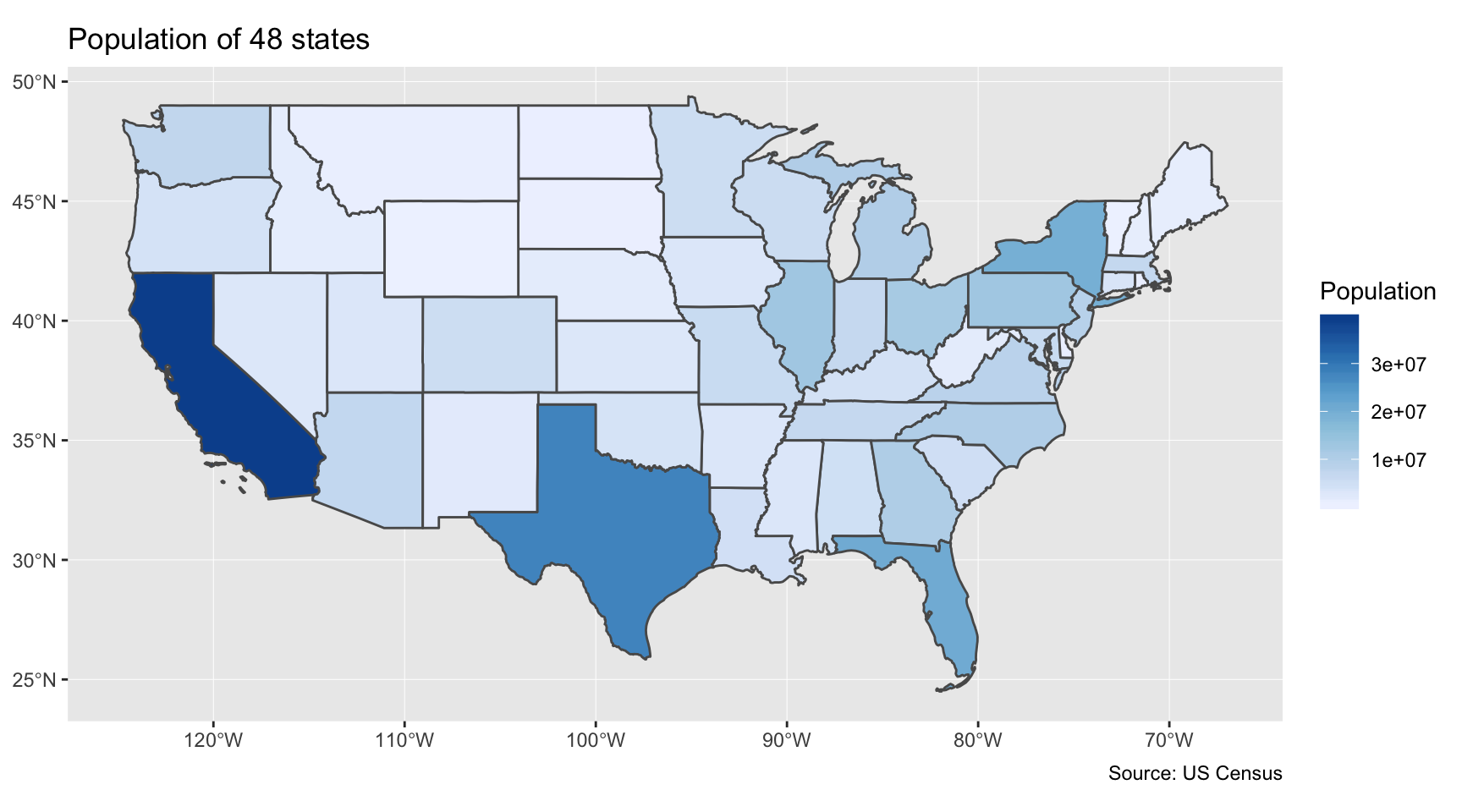
Downloading shape files directly into R
Using the tigris package, which lets us download Census shapefiles directly into R without having to unzip and point to directories, etc.
Simply call any of these functions (with the proper location variables):
tracts()counties()school_districts()roads()
Downloading Texas
First, let’s make sure the shape files download as sf files (because it can also handle sp versions, as well)
If cb is set to TRUE, it downloads a generalized (1:500k) counties file. Default is FALSE (the most detailed TIGER file).
library(tigris)
options(tigris_use_cache = TRUE)
options(tigris_class = "sf")
tx <- counties("TX", cb=T)What the tx object looks like
View(tx)
Looks familiar, right?
When we imported the file locally
fifty_location <- "data/cb_2017_us_state_20m/cb_2017_us_state_20m.shp"
fifty_states <- st_read(fifty_location)
View(fifty_states)
Mapping Texas
ggplot(tx) +
geom_sf() +
theme_void() +
theme(panel.grid.major = element_line(colour = 'transparent')) +
labs(title="Texas counties")
Notes on some code
theme_void() +
theme(panel.grid.major = element_line(colour = 'transparent')) +- theme_void() is a special function that gets rid of grids and gray space for maps
- theme() is how you can alter specific styles of the visualization
- theme_void() is a collection of individual theme() modifications
Time to add some data
Downloading Census data into R via API
Instead of downloading data from the horrible-to-navigate Census FactFinder or pleasant-to-navigate CensusReporter.org we can pull the code with the censusapi package from Hannah Recht, of Bloomberg.
First, sign up for a census key and load it into the environment.
Load the censusapi library
Replace YOURKEYHERE with your Census API key.
# Add key to .Renviron
Sys.setenv(CENSUS_KEY="YOURKEYHERE")
# Reload .Renviron
readRenviron("~/.Renviron")
# Check to see that the expected key is output in your R console
Sys.getenv("CENSUS_KEY")library(censusapi)Look up Census tables
Check out the dozens of data sets you have access to now.
apis <- listCensusApis()
View(apis)
Downloading Census data
We’ll focus on using the getCensus() function from the package. It makes an API call and returns a data frame of results.
These are the arguments you’ll need to pass it:
name- the name of the Census data set, like “acs5” or “timeseries/bds/firms”vintage- the year of the data setvars- one or more variables to access (remember B02001001 from above?)region- the geography level of data, like county or tracts or state
Get Census metadata
Please don’t run this right now.
You can use listCensusMetadata() to see what tables might be available from the ACS Census survey.
acs_vars <- listCensusMetadata(name="acs/acs5", type="variables", vintage=2016)
View(acs_vars)
Downloading median income
tx_income <- getCensus(name = "acs/acs5", vintage = 2016,
vars = c("NAME", "B19013_001E", "B19013_001M"),
region = "county:*", regionin = "state:48")
head(tx_income)## state county NAME B19013_001E B19013_001M
## 1 48 001 Anderson County, Texas 42146 2539
## 2 48 003 Andrews County, Texas 70121 7053
## 3 48 005 Angelina County, Texas 44185 2107
## 4 48 007 Aransas County, Texas 44851 4261
## 5 48 009 Archer County, Texas 62407 5368
## 6 48 011 Armstrong County, Texas 65000 9415Join and map
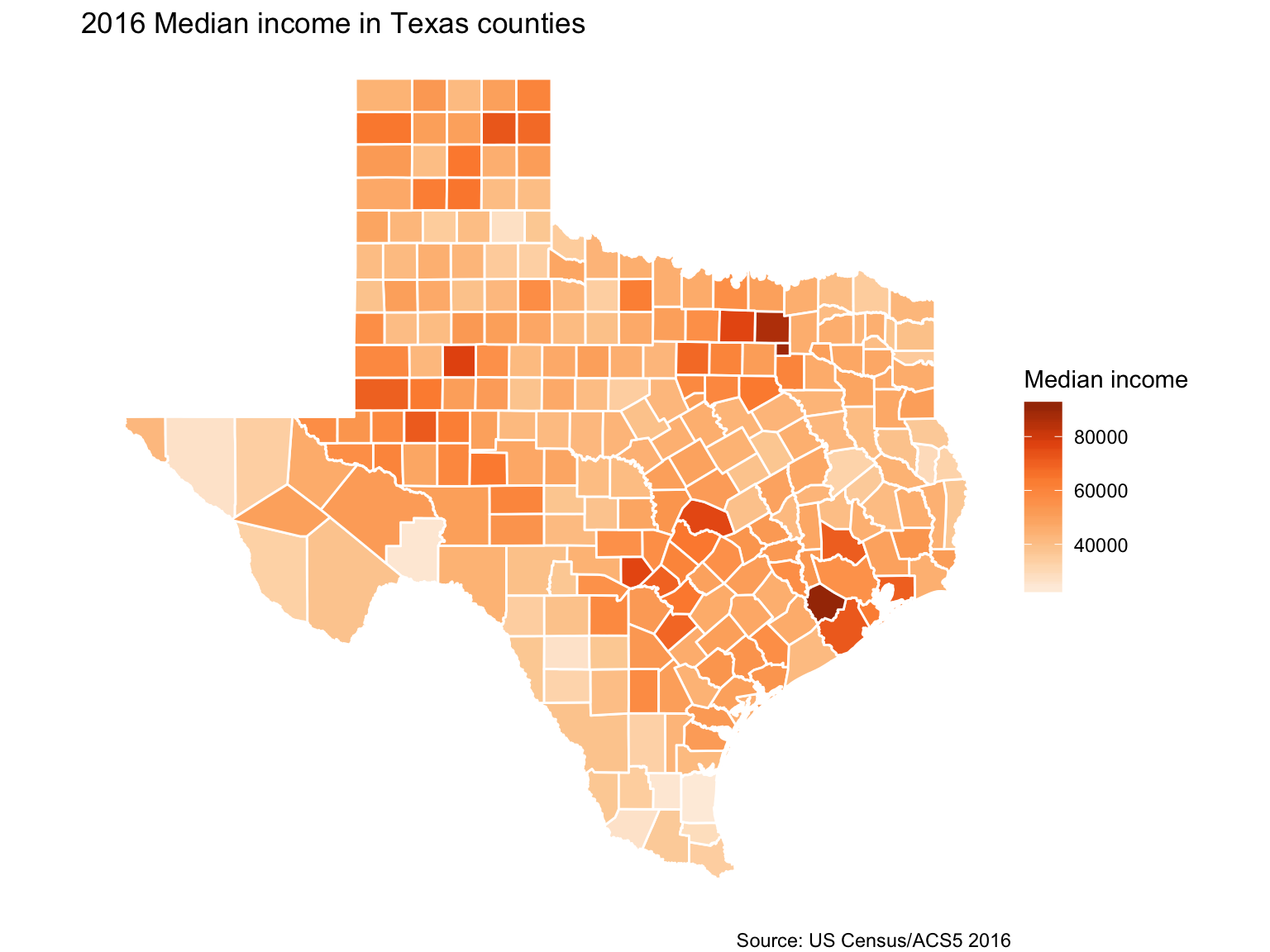
tx4ever <- left_join(tx, tx_income, by=c("COUNTYFP"="county"))
ggplot(tx4ever) +
geom_sf(aes(fill=B19013_001E), color="white") +
theme_void() +
theme(panel.grid.major = element_line(colour = 'transparent')) +
scale_fill_distiller(palette="Oranges", direction=1, name="Median income") +
labs(title="2016 Median income in Texas counties", caption="Source: US Census/ACS5 2016")Texas median income
Download Census data and shapefiles together
Newest package for Census data: tidycensus
With tidycensus, you can download the shape files with the data you want already attached. No joins necessary.
Let’s get right into mapping. We’ll calculate unemployment percents by Census tract in Jersey City. It’ll involve wrangling some data. But querying the data with get_acs() will be easy and so will getting the shape file by simply passing it geometry=T.
Load up tidycensus
library(tidycensus)Pass it your Census key.
census_api_key("YOUR API KEY GOES HERE")Getting unmployment figures
jobs <- c(labor_force = "B23025_005E",
unemployed = "B23025_002E")
jersey <- get_acs(geography="tract", year=2016,
variables= jobs, county = "Hudson",
state="NJ", geometry=T)head(jersey)## Simple feature collection with 6 features and 5 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -74.05794 ymin: 40.74748 xmax: -74.03778 ymax: 40.76072
## epsg (SRID): 4269
## proj4string: +proj=longlat +datum=NAD83 +no_defs
## GEOID NAME variable
## 1 34017000100 Census Tract 1, Hudson County, New Jersey B23025_002
## 2 34017000100 Census Tract 1, Hudson County, New Jersey B23025_005
## 3 34017000200 Census Tract 2, Hudson County, New Jersey B23025_002
## 4 34017000200 Census Tract 2, Hudson County, New Jersey B23025_005
## 5 34017000300 Census Tract 3, Hudson County, New Jersey B23025_002
## 6 34017000300 Census Tract 3, Hudson County, New Jersey B23025_005
## estimate moe geometry
## 1 3488 572 MULTIPOLYGON (((-74.05794 4...
## 2 328 147 MULTIPOLYGON (((-74.05794 4...
## 3 2774 409 MULTIPOLYGON (((-74.05223 4...
## 4 85 69 MULTIPOLYGON (((-74.05223 4...
## 5 2397 305 MULTIPOLYGON (((-74.04682 4...
## 6 158 65 MULTIPOLYGON (((-74.04682 4...Transforming and mapping the data
library(tidyr)
jersey %>%
mutate(variable=case_when(
variable=="B23025_005" ~ "Unemployed",
variable=="B23025_002" ~ "Workforce")) %>%
select(-moe) %>%
spread(variable, estimate) %>%
mutate(percent_unemployed=round(Unemployed/Workforce*100,2)) %>%
ggplot(aes(fill=percent_unemployed)) +
geom_sf(color="white") +
theme_void() +
theme(panel.grid.major = element_line(colour = 'transparent')) +
scale_fill_distiller(palette="Reds", direction=1, name="Estimate") +
labs(title="Percent unemployed in Jersey City",
caption="Source: US Census/ACS5 2016")Transforming and mapping the data
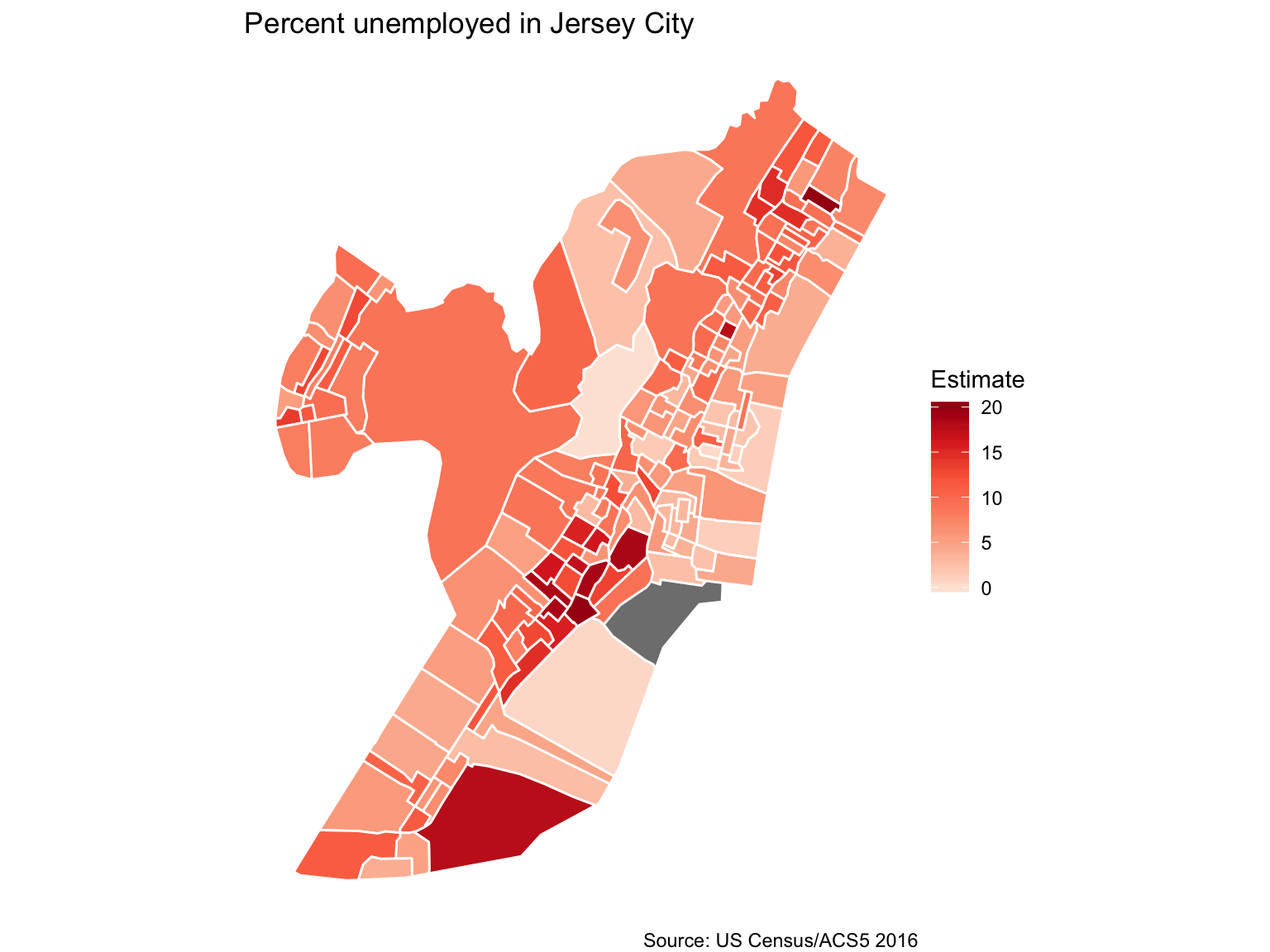
Faceting maps (Small multiples)
racevars <- c(White = "B02001_002",
Black = "B02001_003",
Asian = "B02001_005",
Hispanic = "B03003_003")
harris <- get_acs(geography = "tract", variables = racevars,
state = "TX", county = "Harris County", geometry = TRUE,
summary_var = "B02001_001", year=2017) Faceting maps (Small multiples)
head(harris)head(harris)## Simple feature collection with 6 features and 7 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -95.37457 ymin: 29.74486 xmax: -95.34116 ymax: 29.77055
## epsg (SRID): 4269
## proj4string: +proj=longlat +datum=NAD83 +no_defs
## GEOID NAME variable estimate
## 1 48201100000 Census Tract 1000, Harris County, Texas White 3339
## 2 48201100000 Census Tract 1000, Harris County, Texas Black 780
## 3 48201100000 Census Tract 1000, Harris County, Texas Asian 231
## 4 48201100000 Census Tract 1000, Harris County, Texas Hispanic 995
## 5 48201210100 Census Tract 2101, Harris County, Texas White 2832
## 6 48201210100 Census Tract 2101, Harris County, Texas Black 3029
## moe summary_est summary_moe geometry
## 1 392 4712 480 MULTIPOLYGON (((-95.37457 2...
## 2 268 4712 480 MULTIPOLYGON (((-95.37457 2...
## 3 132 4712 480 MULTIPOLYGON (((-95.37457 2...
## 4 281 4712 480 MULTIPOLYGON (((-95.37457 2...
## 5 587 6252 1029 MULTIPOLYGON (((-95.35934 2...
## 6 574 6252 1029 MULTIPOLYGON (((-95.35934 2...Transforming and mapping the data
library(viridis)
harris %>%
mutate(pct = 100 * (estimate / summary_est)) %>%
ggplot(aes(fill = pct, color = pct)) +
facet_wrap(~variable) +
geom_sf() +
coord_sf(crs = 26915) +
scale_fill_viridis(direction=-1) +
scale_color_viridis(direction=-1) +
theme_void() +
theme(panel.grid.major = element_line(colour = 'transparent')) +
labs(title="Racial geography of Harris County, Texas", caption="Source: US Census 2010")Transforming and mapping the data
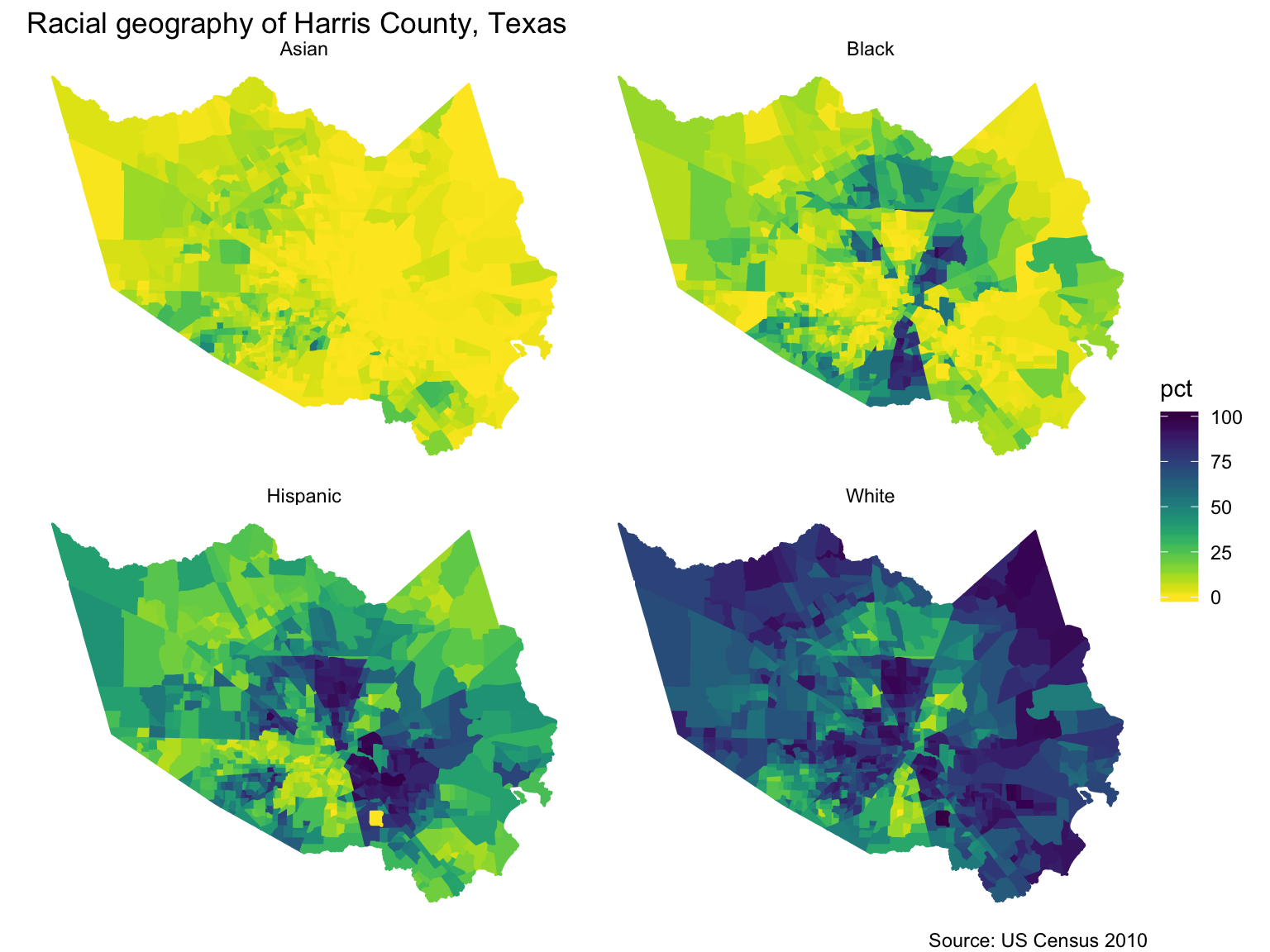
*About Alaska and Hawaii
If you pass shift_geo=T to the get_acs() function in tidycensus then the states will be re positioned.
county_pov <- get_acs(geography = "county",
variables = "B17001_002",
summary_var = "B17001_001",
geometry = TRUE,
shift_geo = TRUE) %>%
mutate(pctpov = 100 * (estimate/summary_est))
ggplot(county_pov) +
geom_sf(aes(fill = pctpov), color=NA) +
coord_sf(datum=NA) +
labs(title = "Percent of population in poverty by county",
subtitle = "Alaska and Hawaii are shifted and not to scale",
caption = "Source: ACS 5-year, 2016",
fill = "% in poverty") +
scale_fill_viridis(direction=-1)Welcome back Alaska and Hawaii

New static map options
- tigris
- censusapi
- tidycensus
- tmap
- urbnmapr (via Urban Institute)
Interactive maps
Leaflet
The Leaflet R package was created by the folks behind RStudio to integrate with the popular opensource JavaScript library.
Essentially, this package lets you make maps with custom map tiles, markers, polygons, lines, popups, and geojson.
Almost any maps you can make in Google Fusion Tables or Carto(DB), you can make in R using the Leaflet package.
Interactive map
Start with the tx shapefile we downloaded via API
leaflet()- initializes the leaflet functionaddTiles()- the underlying map tilesaddPolygons()- instead of dots, we’re adding Polygons, or shapes- Passing the argument
popupto the function with the variable NAME from the shape file
- Passing the argument
library(leaflet)
tx %>%
leaflet() %>%
addTiles() %>%
addPolygons(popup=~NAME)Interactive map
Setting up map options
# Creating a color palette based on the number range in the B19013_001E column
pal <- colorNumeric("Reds", domain=tx4ever$B19013_001E)
# Setting up the pop up text
popup_sb <- paste0("Median income in ", tx4ever$NAME.x, "\n$", as.character(tx4ever$B19013_001E))Map code
addProviderTiles()- instead ofaddTiles()- Uses the Leaflet Providers plugin to add different tiles to map
setView()- sets the starting position of the map- Centers it on defined coordinates with a specific zoom level
- Lots of arguments passed to
addPolygons()fillColor()fillOpacity()weightsmoothFactor()
addLegend()- same as in the previous section but with more customization
Map code
# Mapping it with the new tiles CartoDB.Positron
leaflet() %>%
addProviderTiles("CartoDB.Positron") %>%
setView(-98.807691, 31.45037, zoom = 6) %>%
addPolygons(data = tx4ever ,
fillColor = ~pal(tx4ever$B19013_001E),
fillOpacity = 0.7,
weight = 0.2,
smoothFactor = 0.2,
popup = ~popup_sb) %>%
addLegend(pal = pal,
values = tx4ever$B19013_001E,
position = "bottomright",
title = "Median income")Map
Newer options
Newer options
